One of my duties as a team lead and senior software engineer is reviewing my team’s code.
The following was a task given to a team member:
- The user need to upload user data by excel (user per row)
- if the username exists, update
- if not, create a new user
Proposed code (The wrong way)
The pseudo code written by the junior dev was as below (Some part of the code like data validation and error handling were removed for simplicity):

The developer is using an ORM library to connect to the database, so for him it looked like a straightforward task, call some “repository functions” and it’s done or as we joke internally “Work like a charm”.
Code review
Even if the code looks simple, and works, it’s drastically wrong!
There’s four issues :
- Multiple level of abstraction and a lack of separation of concern: The current code is parsing and doing transactions on the database, which contradict with the “One level of abstraction per function” concept
- Non reusable: If I need to introduce a new type of input files like XML, I will need to rewrite the function and call a different parser
- Bombarding the database: the proposed solution is literally doing three hits per row ( check, update/create and save). Even if we look to the core of the ORM, we will see a lot of opening sessions, ids creation, auto ids incrementing, commits etc. If we have 3000 rows, we can expect 9000 hits on the database.
- Time consuming process: On scale , the process will take too much time, due to the network latency/cost/overhead when hitting the database
Proposed Fix
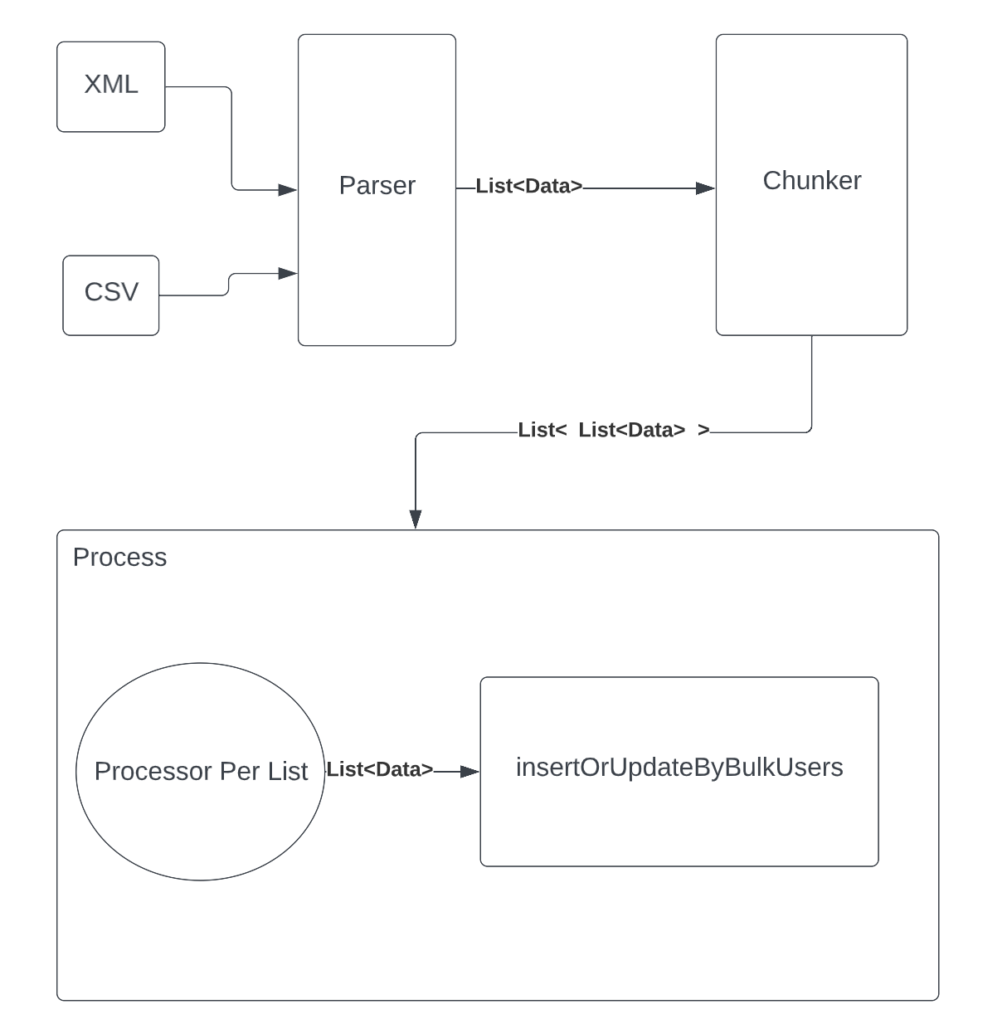
After explaining the issues to the developers I wrote the following code

First of all the parsing process is extracted from the solution. Now it’s possible to introduce a new type of parser (Kindly note that parser is written differently using an abstraction layer but here, I preferred to keep it simple).
After getting the list of users the process will be like this:
- We get the list of all usernames
- We search for them in the database using 1 hit only
- We save and index the list of existing users in memory
- Now we parse the list
- We do the verification in memory instead of database
- We do the transactions on the list of objects
- We save the list in bulk with 1 hit
Many will ask why I added an indexing/mapping process, the idea was reducing the complexity of the code from O(n2) to O(n) using the “memoization” concept. Instead of searching in the list for username. I benefit from the map O(1) search complexity.
Limitations and possible enhancements
Nonetheless, our new solution isn’t perfect. Because technically the enhancements in performance, speed and scalability come at the expense of 2 main elements:
- Memory usage: more memory will be used to save lists and map
- More resources will be consumed temporarily on the database engine on hits